Google just launched multimodal AI embeddings — and it changes the game for how small and mid-size businesses can build intelligent apps that actually understand their data.
If you've ever wished your software could actually understand your business data — not just store it, but search it, reason about it, and answer questions from it — that future just got a lot more accessible.
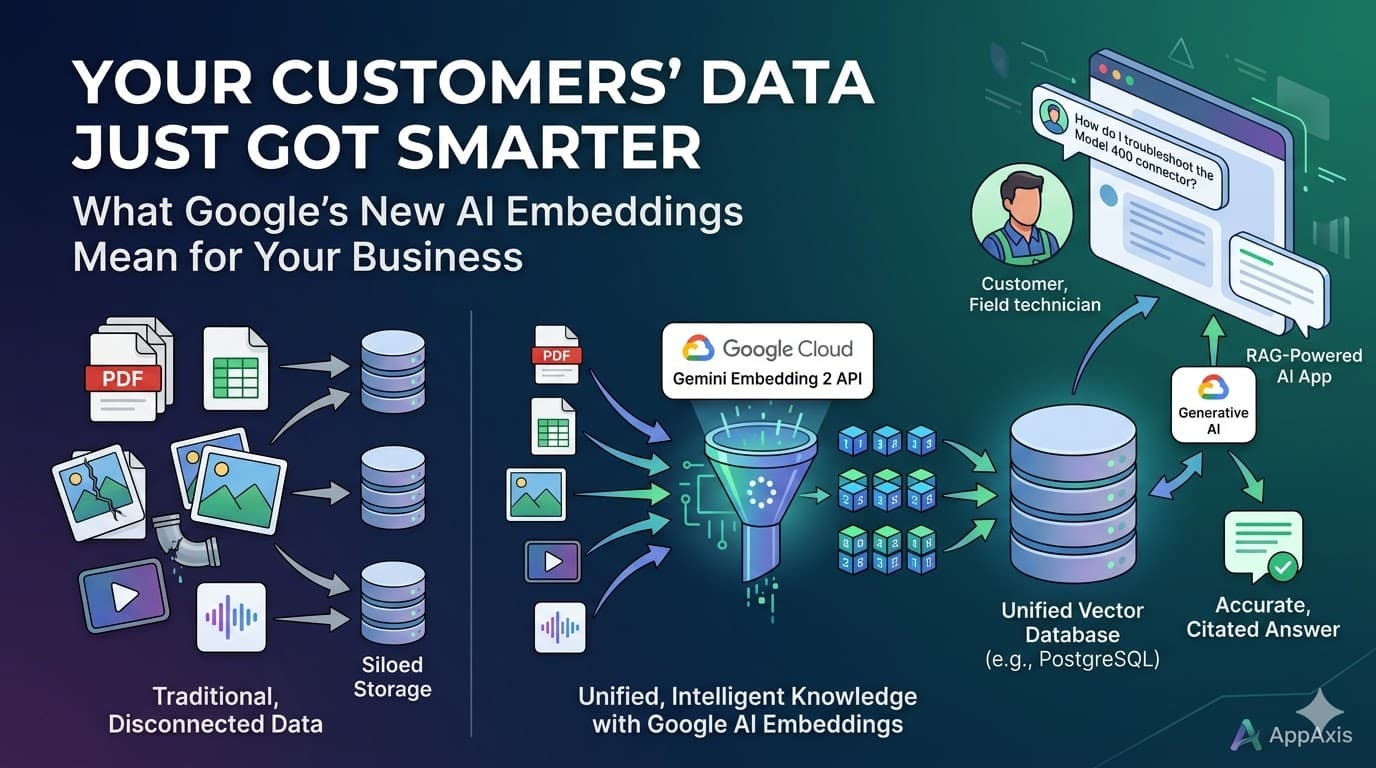
Google recently released Gemini Embedding 2, a new AI model that converts text, images, PDFs, audio, and video into a unified format that machines can search and compare. Combined with a technique called Retrieval-Augmented Generation (RAG), this lets you build apps where an AI model answers questions grounded in your company's data — not generic internet knowledge.
The best part? You don't need a data science team or a seven-figure budget. The tools are available today, the APIs are straightforward, and the infrastructure runs on databases you may already use.
What Are Embeddings (In Plain English)?
Think of embeddings as a translator between human language and math. When you feed a sentence, a PDF, or an image into the embedding model, it returns a list of numbers (a "vector") that captures the meaning of that content.
Two pieces of content that mean similar things will have similar vectors — even if they use completely different words or formats. A photo of a cracked pipe and a maintenance report describing "fractured PVC line" will land near each other in vector space.
This is what makes RAG possible: you store your business data as vectors, and when someone asks a question, the system finds the most relevant pieces and hands them to an AI model to generate a grounded answer.
What Changed — and Why It Matters Now
Until recently, embedding models only handled text. If your business data included images, PDFs, or audio recordings, you needed separate models and separate pipelines to process each format. That complexity put intelligent search out of reach for most SMBs.
Gemini Embedding 2 changes this by mapping all content types into one unified space. Text, images, video, audio, and PDFs all become comparable vectors from a single API call. This dramatically simplifies the architecture and reduces cost.
3 Use Cases That Can Transform Your Business
🎯 Use Case 1: Intelligent Customer Support Portal
The Problem: Your support team answers the same questions repeatedly. Product manuals, troubleshooting guides, training videos, and past ticket resolutions exist — but they're scattered across SharePoint, Google Drive, email, and people's heads. Customers wait. Agents dig.
The Solution: Embed all of your support content — PDFs, knowledge base articles, how-to videos, product images — into a single vector index. When a customer (or agent) types a question, the system retrieves the most relevant content across all formats and generates a specific, cited answer.
Real Impact: A customer types "my device won't connect after the firmware update." The system retrieves the relevant section from the v3.2 release notes PDF, a screenshot from the troubleshooting guide showing the reset sequence, and a resolution note from a similar ticket last month — then synthesizes a step-by-step answer.
🔍 Use Case 2: Internal Knowledge Search for Field Teams
The Problem: Your field technicians, sales reps, or installers need fast answers on the job — specs, compliance docs, pricing, installation procedures — but the information lives in dozens of systems. They call the office, wait, or guess.
The Solution: Build a mobile-friendly internal search tool backed by embeddings. Ingest your SOPs, spec sheets, product catalogs (with images), compliance documents, and training materials. Field teams ask natural language questions and get instant, accurate answers with source references.
Real Impact: A technician on-site asks "what torque spec for the Model 400 flange bolts in a high-pressure application?" The system pulls the relevant page from the engineering spec PDF and the applicable compliance note — no phone call required.
🏢 Use Case 3: Multi-Tenant Client Portals with Per-Customer Intelligence
The Problem: You serve multiple clients, each with their own contracts, configurations, SLAs, and documentation. Your team has to manually look up client-specific details every time someone asks a question. Scaling this with headcount doesn't work.
The Solution: Store each client's data in a shared vector database with tenant isolation (a customer_id filter on every record). When a client logs into their portal and asks a question, the system only searches their data. Each customer gets a personalized AI assistant that knows their account inside and out.
Real Impact: A logistics client asks "what were our on-time delivery rates last quarter?" The system retrieves their performance reports and SLA documents, then generates a summary with the specific numbers — all without exposing any other client's data.
Ready to Make Your Data Work Harder?
At AppAxis, we build AI-powered applications that turn your existing business data into a competitive advantage. Whether you're looking to reduce support costs, empower your field teams, or deliver smarter client experiences — we can get you from concept to working prototype in days, not months.