
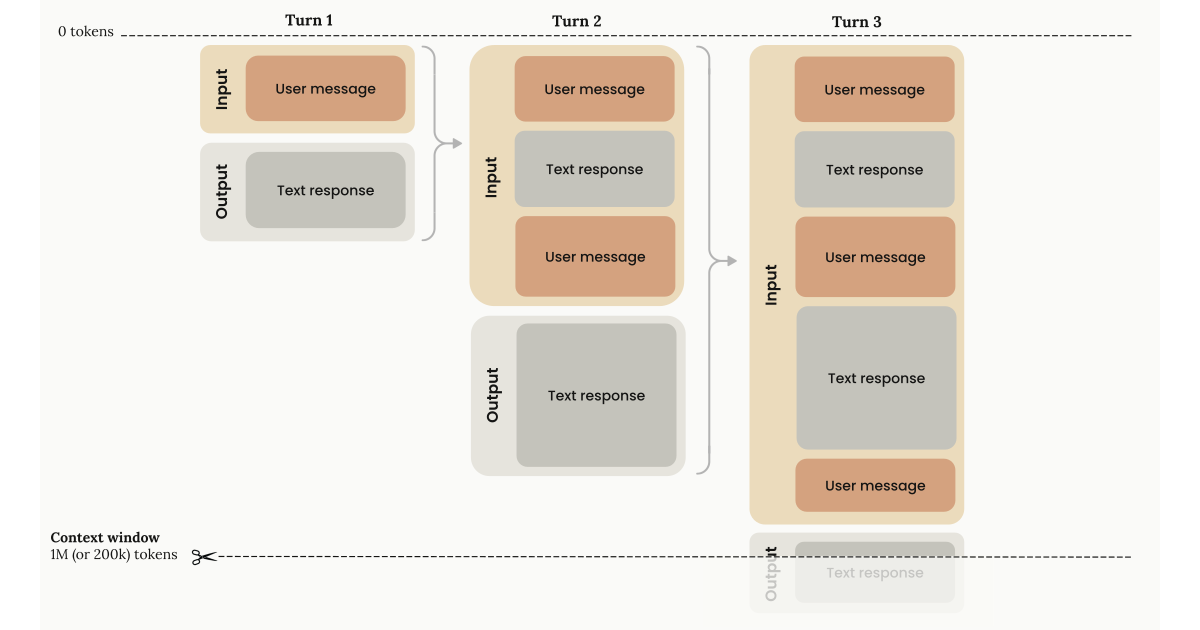
On March 13, Anthropic made the full 1M token context window generally available for Claude Opus 4.6 and Sonnet 4.6 — at the same per-token rate as a 200K request. No multiplier. No premium tier. A 900K-token request costs exactly the same per-token as a 9K-token request.
That’s not an incremental pricing adjustment. That’s a structural shift in what’s economically viable to build with AI.
During the beta, requests over 200K tokens cost 2x on input and 1.5x on output. A 500K-token Opus input that cost $5.00 now costs $2.50. For workloads that routinely exceed 200K tokens — and the ones we care about always do — this halves the input cost overnight.
But the pricing isn’t the real story. The real story is what becomes possible when you can load 3,000 pages of source material into a single AI session with no accuracy degradation, no chunking hacks, and no retrieval pipeline stitching documents together with prayers and embeddings.
Here are the industries where this hits hardest.
Legal: The Entire Case File in One Session
A 1M token context window holds roughly 3,000 pages of text. That’s not a theoretical number — that’s a real contract negotiation. Multiple rounds of a 100-page agreement. All the redlines, all the commentary, all the exhibits.
Before this, legal AI tools had two options: chunk documents and hope the model stitched meaning across boundaries, or build elaborate retrieval pipelines that surfaced “relevant” passages and missed the ones that actually mattered. Every attorney who’s used RAG-based contract analysis has a story about the clause that got missed because the retrieval step decided it wasn’t semantically similar enough to the query.
With 1M context, the chunking problem disappears. The model sees the full arc of a negotiation — the original terms, the counterparty’s redlines, the internal memo explaining why your team pushed back on the indemnification cap, and the final version where the language shifted just enough to create ambiguity three years later. That ambiguity is only visible if you can see the entire history at once.
Where this gets operationally real:
Plaintiff attorneys cross-referencing 400-page deposition transcripts against discovery documents in one pass. Compliance teams reconciling a bank’s internal policies against the full text of Dodd-Frank, the OCC guidance, and the consent order — simultaneously. M&A due diligence teams loading every material contract from a target company’s data room into a single session, asking: “Where are the change-of-control provisions that could trigger assignment restrictions?”
The difference isn’t speed. It’s that the model never loses context on page 47 when it’s analyzing page 312.
Healthcare: A Patient’s Full History, Not a Summary of It
A patient’s complete medical record — years of clinical notes, lab results, imaging reports, prescription history, referral letters, discharge summaries — fits inside a 1M token window.
That changes what’s possible in clinical decision support. Today, most healthcare AI systems work from summaries or structured data extracts. The physician gets a compressed version of the patient’s history, and the model reasons over what someone else decided was important enough to include. If the relevant detail was a throwaway line in a progress note from 18 months ago — the kind of thing a specialist might catch on a second read — it’s gone.
Population health analytics become fundamentally different when you can load an entire patient cohort’s records into a single session. Risk stratification doesn’t have to rely on coded diagnoses and billing data anymore. It can reason over the actual clinical narrative — the social history that mentions the patient lives alone, the nursing note about medication adherence concerns, the pattern of cancelled follow-up appointments that shows up across records but never makes it into a structured field.
Where this gets operationally real:
Clinical trial matching against the full text of a patient’s chart, not a coded problem list. Retrospective chart reviews for quality measures that require understanding context across encounters — the kind that currently take a nurse abstractor two hours per chart. Prior authorization workflows where the AI reads the actual clinical documentation, the payer’s medical policy, and the relevant clinical guidelines in one pass, instead of requiring a human to connect the dots across three different systems.
For organizations navigating FDA regulatory pathways or building SaMD platforms, the ability to load your entire 510(k) submission — predicate device comparisons, bench testing data, clinical validation studies, the full text of the relevant guidance documents — into one session means your regulatory strategy conversations with AI actually have the full picture.
Financial Services: Full Portfolio Analysis Without the Fragmentation
Every quarter, publicly traded companies file 10-Ks that run 200-300 pages. Analyst teams at asset managers cover dozens of companies. The analysis that matters isn’t what’s in any single filing — it’s the patterns across filings, the year-over-year changes in risk factor language, the footnote disclosures that contradict management commentary three sections earlier.
Before 1M context, portfolio-level analysis with AI meant either heavily summarized inputs or elaborate orchestration layers that queried across document stores. Both approaches lose signal. The summarization throws away nuance. The orchestration introduces latency and retrieval errors.
Now you can load a company’s last four annual filings — or a portfolio of ten companies’ most recent 10-Ks — into a single session and ask questions that span the entire corpus. “Which of these companies increased their goodwill impairment risk language between fiscal year 2024 and 2025, and how does that correlate with their reported segment performance?”
Where this gets operationally real:
AML/KYC teams processing an entire suspicious activity investigation — transaction logs, customer communications, correspondent banking records, and the relevant regulatory guidance — without breaking the analysis into chunks that lose the thread. Audit teams loading a complete set of financial statements, the prior year’s management letter, the current year’s work papers, and the applicable accounting standards into one session. Insurance underwriters analyzing a commercial account’s complete loss history, policy endorsements, engineering reports, and market data simultaneously.
68% of banks plan to adopt long-context LLMs for risk management by 2026. The math is straightforward: when your compliance team spends four hours manually cross-referencing a 500-page regulatory filing against internal controls documentation, and an AI can do the same analysis in minutes with the full text of both in context, the ROI calculation writes itself.
Manufacturing and IoT: Entire System Histories, Not Dashboard Snapshots
A typical manufacturing facility generates enormous volumes of operational data — equipment telemetry, maintenance logs, quality inspection records, shift reports, SCADA system events. The diagnostic insights that prevent unplanned downtime aren’t in any single data stream. They’re in the correlations across streams that no dashboard can visualize because they span different systems, different time horizons, and different data formats.
With 1M context, you can load six months of maintenance logs for a production line alongside the corresponding quality data, operator notes, and equipment sensor readings. The model can identify the pattern that your best maintenance technician knows intuitively but can’t articulate: that a specific combination of vibration readings, ambient temperature changes, and a subtle shift in cycle time — spread across three different data sources — precedes a bearing failure by 72 hours.
Where this gets operationally real:
Root cause analysis across an entire incident timeline — not a summary of it. Loading the full SCADA event log, the operator’s shift report, the maintenance work order history, and the quality deviation report into one session. Fleet management operators analyzing a driver’s complete trip history, vehicle maintenance records, fuel consumption data, and ELD compliance logs to understand why one route consistently underperforms.
The gap between your best technician’s 90% first-time fix rate and your average technician’s 40% stops being an unexplainable mystery when you can feed the AI enough operational history to find the diagnostic patterns that experience teaches.
Software Development: Your Codebase, Not a Fragment of It
This is where the 1M context window might have the most immediate, measurable impact. A million tokens holds roughly 30,000-40,000 lines of code — an entire mid-sized application. Not selected files. Not a retrieval-augmented subset. The whole thing.
Developers working with AI coding tools have lived with a fundamental limitation: the model could only see a few files at a time. It could refactor a function, but it couldn’t understand the architectural implications across the codebase. It could suggest a fix, but it couldn’t trace the dependency chain five modules deep to find the actual root cause.
As one engineer put it: “Claude Code can burn 100K+ tokens searching databases and source code. Then compaction kicks in. Details vanish. With 1M context, I search, re-search, and propose fixes in one window.”
Where this gets operationally real:
Loading an entire microservices application — all services, shared libraries, infrastructure configuration, and test suites — into a single session for architecture review. Migration projects where the model needs to understand both the legacy codebase and the target framework simultaneously. Security audits that trace data flow from API endpoint through middleware, business logic, data access layer, and database queries without losing context at any boundary.
Opus 4.6 scores 78.3% on MRCR v2 — the long-context retrieval benchmark — the highest among frontier models at that context length. That means it’s not just holding more tokens. It’s actually using them accurately at the far edges of the window.
What This Means for How You Build
The 1M context window doesn’t just make existing AI workflows faster. It eliminates entire categories of engineering complexity.
RAG pipelines that chunk, embed, retrieve, and re-rank are engineering-intensive and inherently lossy. They were necessary when context windows were 8K or even 128K. At 1M tokens, many of those pipelines become unnecessary overhead — you can just load the source material directly.
That doesn’t mean RAG is dead. If your corpus is tens of millions of documents, you still need retrieval. But for the workloads that most enterprises actually run — analyzing a specific contract, reviewing a specific patient’s records, auditing a specific codebase — the source material fits in context. The whole thing. No chunking. No retrieval errors. No “the model missed this clause because the embedding didn’t surface it.”
The competitive context matters too. Google’s Gemini 2.5 Pro offers 1M tokens but still charges a premium above 200K. OpenAI’s GPT-5.4 tops out at 128K. When Anthropic made the 1M window standard-priced, they didn’t just improve a feature — they changed the unit economics of every workflow that requires large-context reasoning.
If your operations involve documents measured in hundreds of pages, compliance requirements that span multiple regulatory frameworks, codebases with thousands of files, or diagnostic processes that require correlating data across systems — this is the infrastructure shift that makes AI economically viable for problems you’ve been solving manually.
Not because the AI got smarter. Because it can finally see the whole picture at once, and you don’t have to pay a premium for the privilege.
We build platforms that put these capabilities to work in specific industries, with the operational context to know which problems are worth solving first. If you’re thinking about what 1M context means for your operations, start a conversation. No sales pitch. No pressure. Just a conversation about what you’re trying to build.